Agentic Vision 模式
Agentic Vision 模式是基於 Gemini 3 Flash Agentic Vision 的智慧對話功能,讓 AI 能夠「主動調查」圖片內容,而非被動回答問題。
什麼是 Agentic Vision?
傳統的視覺 AI 只是被動地「看」圖片,然後立即給出答案。Agentic Vision 則將視覺理解轉變為主動調查過程——AI 會像偵探一樣,透過多個步驟來分析、驗證並回答你的問題。
Think → Act → Observe 循環
Agentic Vision 的核心是一個嚴謹的推理循環:
- Think(思考):AI 分析你的問題和圖片,制定多步驟計畫
- Act(行動):AI 編寫並執行 Python 程式碼來處理圖片——裁切放大、進行計算、計數物件、繪製標註
- Observe(觀察):處理後的圖片被放回對話中,AI 檢視結果後再決定下一步
這個循環會持續進行,直到 AI 有足夠的信心給出最終答案。
主要功能
放大檢視(Zoom and Inspect)
當細節太小看不清楚時,AI 會自動偵測並裁切放大該區域:
- 儀表板上的讀數
- 產品標籤上的序號
- 照片角落的小字
視覺數學(Visual Math)
AI 可以進行多步驟計算,並使用 Python 確保精確度:
- 計算收據上的項目總和
- 根據圖表數據繪製新的視覺化圖形
- 測量圖片中的距離或比例
圖片標註(Image Annotation)
AI 可以直接在圖片上繪製標註:
- 箭頭指向重點區域
- 邊界框圈選特定物件
- 文字說明標籤
基本用法
- 選擇「Agentic Vision」模式
- 上傳圖片(可選)
- 輸入你的問題或任務
- AI 會顯示思考過程,並在需要時執行程式碼
- 可以繼續對話,進行後續提問
AI 會根據你的需求自動執行 Python 程式碼來分析圖片。
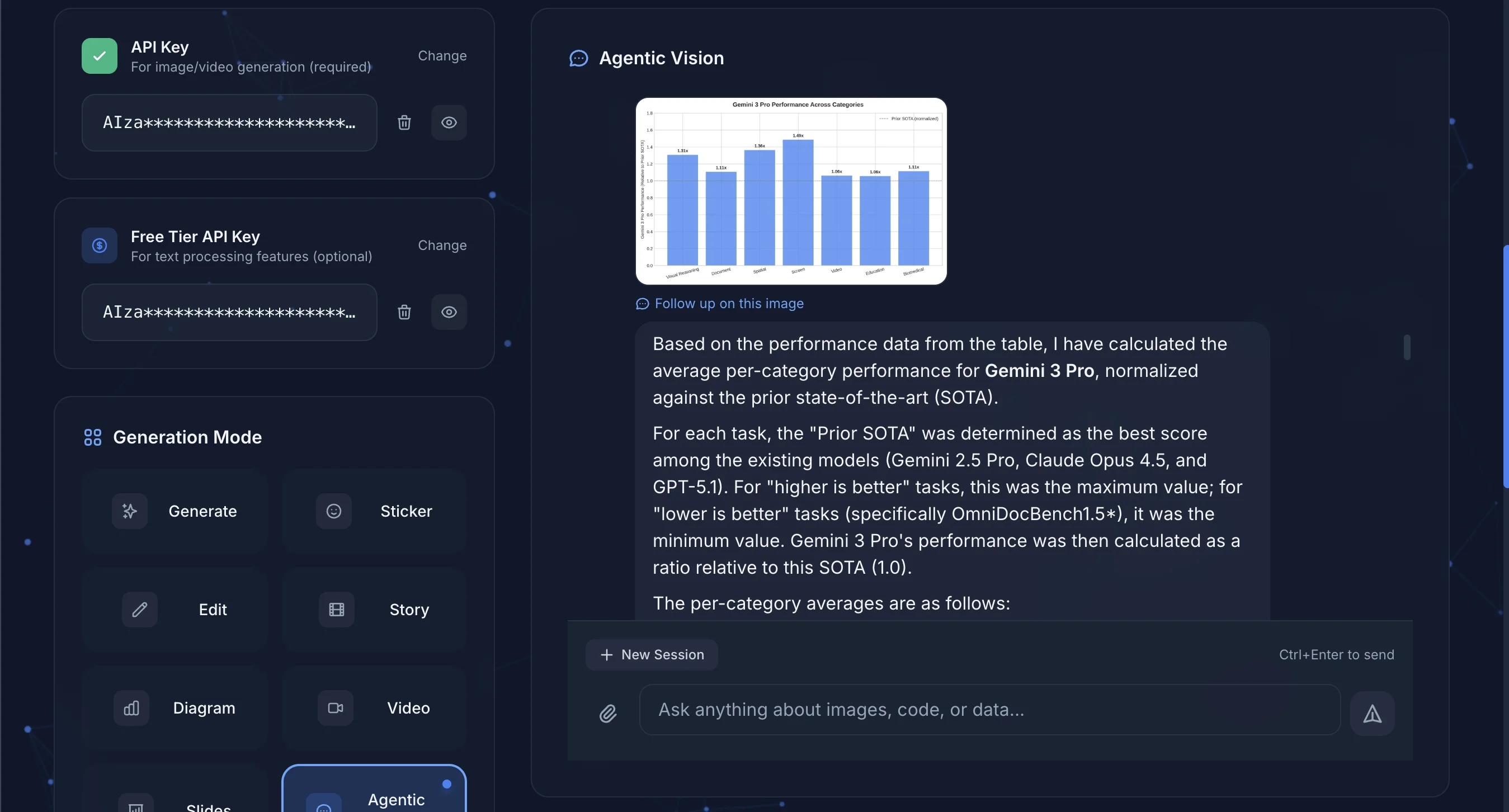
完成分析後,AI 會呈現視覺化結果與詳細說明。
對話設定
上下文深度
控制 AI 能「記住」多少對話歷史(1-10):
- 1-3:適合簡單問答,節省 token
- 5(預設):適合一般對話
- 10:適合複雜的多輪分析
在上下文中包含圖片
當啟用時,AI 在每次回應都會參考之前對話中的圖片。這有助於:
- 跨回合比較不同圖片
- 針對同一張圖進行多角度分析
注意
包含圖片會消耗較多 token,建議在不需要圖片參考時關閉。
AI 思考過程
在 AI 回應時,你可以看到「思考中」的展開區塊,點擊可查看:
- AI 的推理過程
- 計畫的執行步驟
- 程式碼執行結果
這讓你能夠理解 AI 是如何得出答案的,增加可信度。
程式碼執行
當 AI 執行 Python 程式碼時,會顯示:
- 完整的程式碼內容
- 執行結果(文字輸出或圖片)
程式碼在 Google 的安全沙箱中執行,支援常見的資料分析套件如 NumPy、Pandas、Matplotlib 等。
對話管理
開始新對話
點擊「新對話」按鈕會:
- 清除當前對話內容
- 重置對話上下文
- 自動儲存前一個對話(如有內容)
歷史記錄
每個對話都會自動儲存到歷史記錄中,包含:
- 對話縮圖(第一張圖片)
- 對話摘要(第一則訊息的前 200 字)
- 訊息數量
- AI 的思考過程
使用案例
資料分析
上傳包含數據的圖片(表格、圖表、報告),讓 AI 進行分析:
請分析這張銷售報表,計算各產品的總銷售額,
並以圓餅圖呈現各產品的佔比圖片處理
請 AI 處理或標註圖片:
請在這張建築平面圖上標出所有的安全出口,
並計算從最遠的房間到出口的最短距離教學輔助
上傳題目圖片,請 AI 詳細解說:
請一步一步解釋這道數學題的解法,
在需要的地方畫出圖解價格
Agentic Vision 模式使用 Gemini 3 Flash 模型,按 token 計費。啟用程式碼執行會略微增加 token 使用量,因為需要傳送程式碼和結果。
省錢技巧
- 減少上下文深度可降低每次請求的 token 量
- 不需要圖片參考時,關閉「在上下文中包含圖片」